Access to tools is what turns an LLM into an agent. But loading too many tools into context can turn an agent into an expensive slop machine. As Anthropic emphasized in the post Writing Effective Tools, building an effective toolset for an agent requires thinking like an agent.
While testing MCP servers with agents and improving them through agents is inevitable, there are valuable insights to be gained from a human review. This post takes a manual approach to examining the Linear MCP server, exploring what we can learn just by looking at its structure, tool definitions, and design choices. Of course, for comprehensive evaluation, running this server with an actual agent is essential, but even before that step, certain patterns emerge.
Why Linear? In developer communities, Linear consistently comes up as one of the MCP servers that genuinely improves productivity. It lets users query tickets, create issues, and update statuses directly from their IDE. We at Fiberplane use Linear for project management. We’re also big fans of how the MCP integration brings Linear’s functionality straight into the IDE, reducing context switching. That makes Linear an ideal candidate for exploring what good MCP design looks like.
What can be analyzed in an MCP Server
Taking Anthropic’s tips for crafting agent-friendly tools, we can review the Linear MCP server with a few (anti-)patterns in mind:
- API Endpoints vs. MCP Tools: A thoughtful implementation doesn’t simply wrap every available endpoint as a separate tool. We should compare the underlying API surface with the MCP tool set: Are all endpoints exposed? Are related operations consolidated? How many tools exist, and is that number optimized for effective context management?
- Input Parameter Validation and Error Messages: Using the MCP Inspector, we can evaluate how the server handles inputs: Are parameters clearly defined? Does the validation provide helpful feedback? Do error messages guide the agent toward correct usage?
- Output Structure and Signal Quality: We can examine what the server returns: Is the output format consistent and well-structured? Does it contain high-signal information that agents can actually use, or is it cluttered with noise?
The following review focuses on what the MCP Inspector reveals about Linear’s implementation across these three dimensions.
Linear’s MCP Server: A First Look
The Linear MCP server exposes 23 tools that cover the most common Linear workflows. These tools fall into several categories:
- Querying entities: list_issues, list_projects, list_teams, list_users, list_documents, list_cycles, list_comments, list_issue_labels, list_issue_statuses, list_project_labels
- Reading details: get_issue, get_project, get_team, get_user, get_document, get_issue_status
- Creating: create_issue, create_project, create_comment, create_issue_label
- Updating: update_issue, update_project
- Knowledge tools: search_documentation
Consider a typical agent workflow: A developer asks their AI assistant to “create a linear ticket for the authentication work we just discussed and assign it to Sarah.” The agent would:
- Use
list_usersto find Sarah’s ID - Use
list_teamsto identify the correct team - Use
list_issue_labelsto find the “bug” label - Call
create_issuewith the gathered IDs
Or when a time-pressed developer asks “what are the lowest effort open issues assigned to me?”, the agent would:
- Call
list_issueswith assignee set to “me” (the server accepts “me” as a value) - Query
list_issue_labelsto find any like “low hanging fruit” - Analyze complexity of the issue descriptions, possibly doing research in the codebase
These workflows demonstrate how the MCP server’s tools are designed for task completion rather than raw API access. With this context in mind, let’s examine how Linear’s implementation compares to its underlying API.
API Endpoints and MCP Tools
Linear has a GraphQL API. Comparing Linear’s GraphQL API and Linear’s MCP server, the MCP server is doing more than just a simple 1:1 mapping to the GraphQL schemas. Here are the key differences:
Simplified filtering/querying
The list tools (list_issues, list_projects, etc.) provide curated parameter sets rather than exposing Linear’s full GraphQL filter capabilities. For example, list_issues has specific filters like teamId, stateId, assigneeId rather than the complex nested filter objects GraphQL typically uses.
For instance, filtering issues by assignee in the GraphQL API requires a nested filter object:
query {
issues(filter: {
assignee: {
id: { eq: "user-uuid" }
}
}) {
nodes { id, title }
}
}The MCP server simplifies this to a flat parameter:
{
"assigneeId": "user-uuid",
"limit": 50
}This flattening reduces the cognitive load for agents. Fewer nested structures mean fewer tokens and clearer parameter requirements.
Knowledge tools
The search_documentation tool adds Linear’s documentation to the MCP server and provides information that their core API doesn’t contain.
Explicit value mappings
The MCP server documents parameter values directly in tool descriptions. For example, priority is explicitly defined as 0 = No priority, 1 = Urgent, 2 = High, 3 = Normal, 4 = Low, making these mappings immediately clear to agents without requiring external documentation lookups.
This is a thoughtfully designed abstraction layer, not just a mechanical mapping. It makes Linear easier to use by providing task-oriented tools rather than schema-oriented access.
Context cost of tool definitions in practice
The MCP server’s 23 tools come with a tangible context cost.
To measure the context cost, we can add Linear’s MCP server to Claude Code and inspect the /context command, which reveals how tokens are allocated.
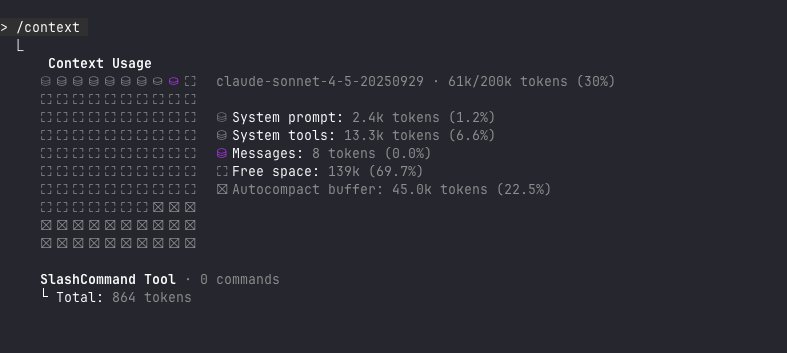
The image above shows the context usage without the MCP Server added. Let’s add the MCP server and inspect the context again:
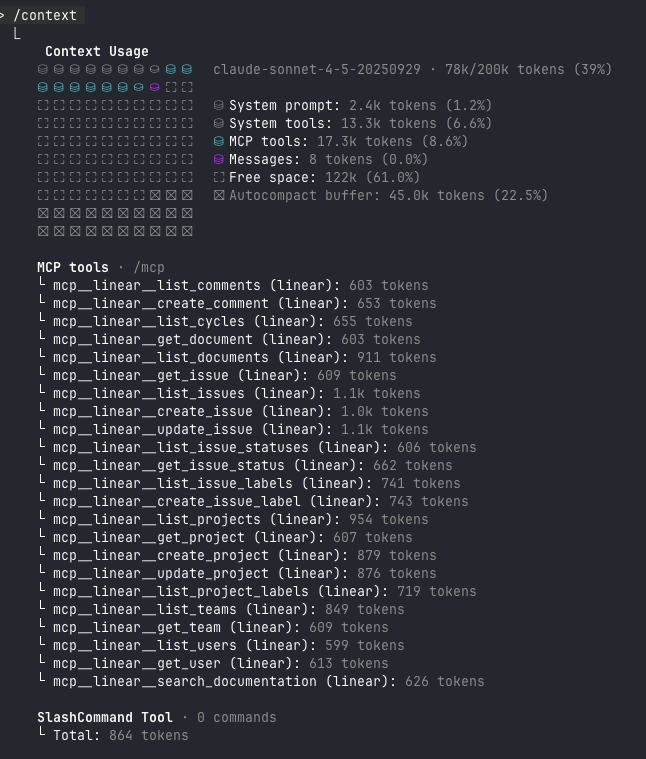
Adding the Linear MCP server increases context usage from 61k to 78k tokens (30% to 39% of the 200k budget), with the tool definitions themselves consuming 17.3k tokens (8.6%). This overhead is the price of having 23 well-documented functions available—each with parameter descriptions, validation rules, and usage examples.
This highlights an important trade-off in MCP server design: comprehensive tooling provides flexibility but consumes context budget. The 17.3k token investment for Linear’s tools is reasonable given the functionality, but it underscores why thoughtful API consolidation matters. Every additional tool definition adds to this baseline cost before any actual work begins.
Different agents handle context differently—some may have larger windows, others more aggressive compression strategies—but the fundamental principle remains: tool definitions are not free. This makes the case for the design choices we see in Linear’s MCP server: consolidating related operations, flattening nested parameters, and providing only the most essential tools rather than exposing the entire API surface.
Input Parameter Validation and Error Messages
The Linear MCP server provides helpful validation feedback. For non-required fields, validation is strict and informative. Pagination cursors (before and after) must be valid UUIDs, and color codes require proper hexadecimal format:
// Input with invalid pagination cursor
{
"limit": 50,
"before": "not-a-uuid",
"orderBy": "updatedAt"
}
// Output
"Error": "Argument Validation Error - before is not a valid pagination cursor identifier."For required fields like entity IDs, malformed values return clear messages like "Entity not found: Project" (though this doesn’t distinguish between validation failures and genuinely missing entities). The error messages provide agents with enough context to quickly identify and resolve issues.
MCP Server Output
When it comes to server output, there are two aspects worth examining. While Linear’s MCP server demonstrates thoughtful design in many areas, the output structure presents opportunities for improvement that could meaningfully reduce token costs and improve context efficiency.
High Signal Information
Responses like list_users return comprehensive fields including createdAt, updatedAt, avatarUrl, isAdmin, isGuest, and detailed status information. When an agent simply wants to assign an issue to a user, fields like avatar URLs and timestamps add noise rather than value.
Additionally, implementing a ResponseFormat enum could control verbosity, offering both concise and detailed response modes depending on the use case.
Output Format
The Linear MCP server returns data wrapped in a nested structure where the actual content is stringified JSON inside a "text" field:
// Input
{
"query": "fiberplane"
}
// Output
{
"content": [
{
"type": "text",
"text": "{\"id\":\"xxxx-xxx-xxx-xxxx-xxxxxxxxx\",\"icon\":\"Chip\",\"name\":\"Fiberplane\",\"createdAt\":\"2020-03-22T17:42:34.376Z\",\"updatedAt\":\"2025-10-20T02:14:34.144Z\"}"
}
]
}From the model’s perspective, this means it doesn’t see structured JSON; it sees a string of escaped characters, such as \"id\":\"123\", rather than { "id": "123" }.
The model must therefore implicitly “unescape” and interpret this data token by token, which increases parsing complexity and context cost.
For large or repetitive responses like list_users or list_issue_labels this stringified format can significantly inflate token usage and degrade reasoning performance.
Studies such as Wang et al. (2025) compare text-serialization formats in terms of computational and representational efficiency across systems. It’s not surprising that LLM-focused research and practical experiments reach the same conclusion — more compact, regular formats like CSV or TSV tend to be both cheaper in tokens and easier for models to interpret than deeply nested or stringified JSON. This pattern is echoed in applied analyses such as Axiom’s MCP efficiency research, and David Gilbertson’s token-cost comparison.
Since Linear operations often return lists of structured entities (for example, users: id / name / email, or labels: name / color / description), there are two distinct approaches to improve context efficiency:
-
Structured Content: The MCP specification provides a structured content feature that allows servers to return native data structures instead of stringified JSON. This would eliminate serialization overhead entirely by providing models with actual structured data rather than escaped strings. The current Linear implementation does not use this approach.
-
Compact Text Formats: For servers that return text-based responses, adopting more compact formats like CSV or TSV can meaningfully reduce token costs compared to deeply nested JSON. Linear’s operations return lists of structured entities such as
users: id/ name/ email, orlabels: name/ color/ description, making tabular formats like CSV relevant for this use case.
Client side: Model dependent format handling
When using text-based serialization formats (such as CSV, JSON or XML), different language models vary in how they process these formats. Research on nested data format comprehension shows model-specific preferences: YAML performed best for GPT-5 Nano and Gemini 2.5 Flash Lite, while Markdown proved most token-efficient across all tested models (using 34-38% fewer tokens than JSON). For nested data, XML consistently underperformed. However, research on tabular data formats found XML performed well (56.0% accuracy, second only to Markdown key-value pairs), though this was only tested with GPT-4.1-nano. According to these two articles, CSV excels for tabular data while Markdown performs best for nested data in terms of token efficiency.
Format choice affects not only token efficiency but also accuracy. He et al. (2024) found that prompt formatting alone—for example, writing data in Markdown, YAML, or JSON can swing task accuracy by up to 40%, with performance varying significantly by model and task. This underscores how sensitive LLMs are to both data serialization and prompt design.
When building MCP servers, we can’t control which model the client uses, so simpler, flatter data representations tend to be the safest choice for broad compatibility.
Conclusion
The Linear MCP server demonstrates thoughtful design that goes beyond simple API wrapping. Its abstraction layer over GraphQL provides task-oriented tools with simplified filtering, convenience methods, and human-friendly documentation—making it genuinely useful for agent-driven workflows.
Two areas warrant attention: high-signal information and output structure. Reducing low-signal data (such as avatar URLs when agents only need to assign users) and adopting more token-efficient formats like CSV for large datasets would meaningfully improve context efficiency and reduce token costs.
A manual review offers a practical first step for identifying optimization opportunities. As Anthropic’s research has shown, agents interpret responses in remarkably human-like ways. What’s clear and efficient for humans often translates well for agents. By examining tool definitions, parameter validation, and output structure, we can spot inefficiencies before running agent interactions.
However, a manual review has limits. The real test comes from dynamic evaluation—running servers with agents in actual workflows, measuring token consumption, and identifying where context management breaks down. Only then can we validate whether a review translates into measurable improvements.